Abstract

Current learning-based subject customization approaches, predominantly relying on U-Net architectures, suffer from limited generalization ability and compromised image quality. Meanwhile, optimization-based methods require subject-specific fine-tuning, which inevitably degrades textual controllability. To address these challenges, we propose InstantCharacter—a scalable framework for character customization built upon a foundation diffusion transformer. InstantCharacter demonstrates three fundamental advantages: first, it achieves open-domain personalization across diverse character appearances, poses, and styles while maintaining high-fidelity results. Second, the framework introduces a scalable adapter with cascaded transformer encoders, which effectively processes open-domain character features and seamlessly interacts with the latent space of modern diffusion transformers. Third, to effectively train the framework, we construct a large-scale character dataset containing 10-million-level samples. The dataset is systematically organized into paired (multi-view character) and unpaired (text-image combinations) subsets. This dual-data structure enables simultaneous optimization of identity consistency and textual editability through distinct learning pathways. Qualitative experiments demonstrate InstantCharacter's advanced capabilities in generating high-fidelity, text-controllable, and character-consistent images, setting a new benchmark for character-driven image generation.
Method
Modern DiTs have demonstrated unprecedented fidelity and capacity compared to traditional UNet-based architectures, offering a more robust foundation for generation and editing tasks. However, existing methods are primarily UNet-based and face a fundamental trade-off between character consistency and image fidelity, limiting their ability to generalize across open-domain characters. Moreover, no prior work has successfully validated character customization on large-scale diffusion transformers (e.g., 12B parameters), leaving a significant gap in the field. Building upon these advances, we present InstantCharacter, a novel framework that extends DiT for generalizable and high-fidelity character-driven image generation. InstantCharacter's architecture centers around two key innovations. First, a scalable adapter module is developed to effectively parse character features and seamlessly interact with DiTs latent space. Second, a progressive three-stage training strategy is designed to adapt to our collected versatile dataset, enabling separated training for character consistency and text editability. By synergistically combining flexible adapter design and phased learning strategy, we enhance the general character customization capability while maximizing the preservation of the generative priors of the base DiT model. In the following sections, we will detail the adapter's architecture and elaborate on our progressive training strategy.
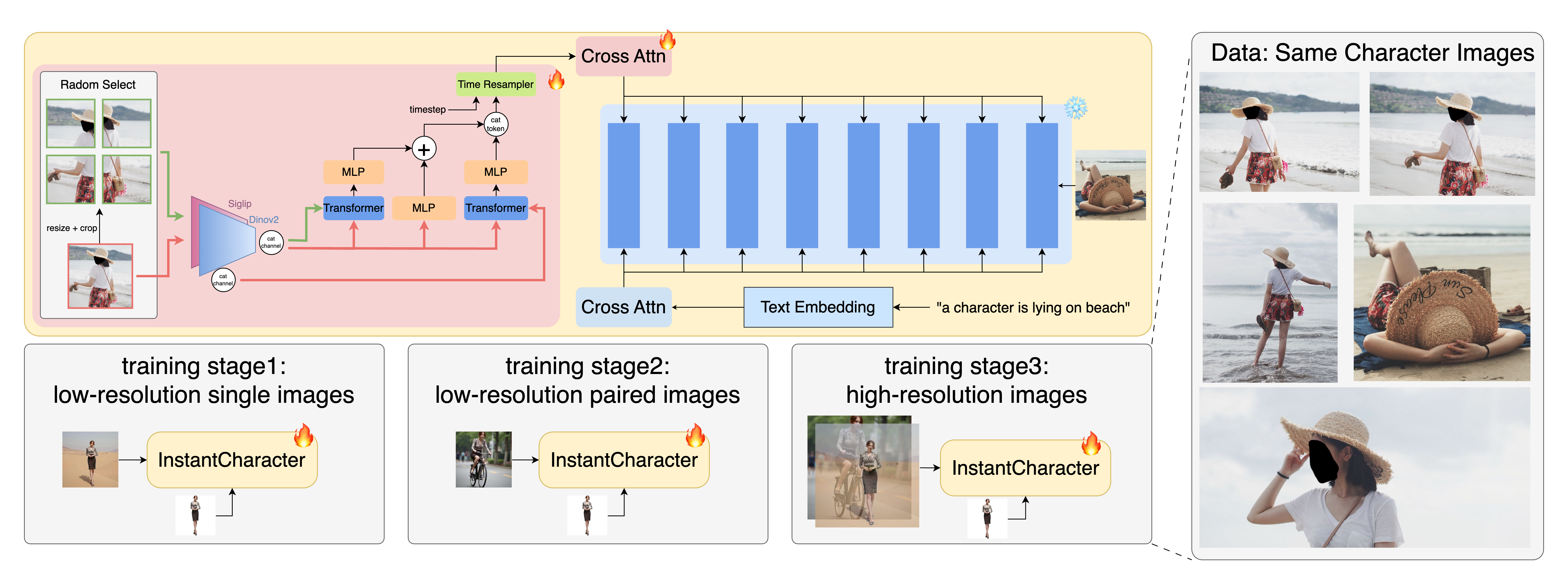

Our framework seamlessly integrates a scalable adapter with a pretrained DiT model. The adapter consists of multiple stacked transformer encoders that incrementally refine character representations, enabling effective interaction with the latent space of the DiT. The training process employs a three-stage progressive strategy, beginning with unpaired low-resolution pretraining and culminating in paired high-resolution fine-tuning.
▶ Qualitative results

▶ Comparison with Other Works

BibTeX
@article{tao2025instantcharacter,
title={InstantCharacter: Personalize Any Characters with a Scalable Diffusion Transformer Framework},
author={Tao, Jiale and Zhang, Yanbing and Wang, Qixun and Cheng, Yiji and Wang, Haofan and Bai, Xu and Zhou, Zhengguang and Li, Ruihuang and Wang, Linqing and Wang, Chunyu and others},
journal={arXiv preprint arXiv:2504.12395},
year={2025}
}